
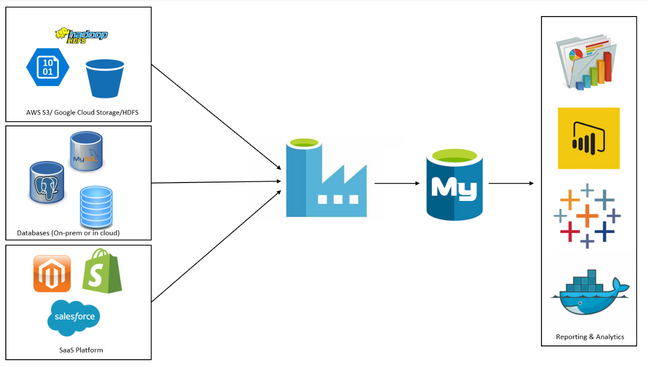
Data is at the forefront of many business decisions nowadays. However, data is not useful if it is not processed appropriately. Building a data pipeline using Microsoft Azure is an efficient way to process data as it can scale up or down as required, and it can be implemented quickly. Azure provides a platform for all stages of the pipeline, from sourcing and transformation to deployment and monitoring. In this article, we will explore the steps involved in building a data pipeline with Microsoft Azure.
Step 1: Setting up your Azure account and resources
The first step in building a data pipeline with Microsoft Azure is setting up an account in the Azure portal. After creating an account, the next step is to create a resource group, which is a logical container for resources such as data factories, storage accounts, and virtual machines. Once you have created a resource group, you can start creating data factories and datasets.
Azure Account Creation
Azure Resource Manager
Azure Services Overview
Step 2: Creating a data factory and defining datasets
Data factories are the backbone of data pipelines. They are where you define the workflow and the resources that the pipeline will use. To create a data factory, navigate to the resource group and select the ‘Add’ button. Next, search for ‘Data Factory’ and select the option to create a new factory. After creating the data factory, you can start defining datasets that will be used as inputs and outputs for the pipeline.
Create a Data Factory
Data Factory Concepts
Creating Datasets in Data Factory
Step 3: Building pipelines to move and transform data
Pipelines define the workflow for moving and transforming data. Once you have defined your data sources and destinations, you can start building pipelines that extract data from sources, transform the data, and load it into destinations. Azure Data Factory provides a drag-and-drop interface for building pipelines, making it easy to create even complex workflows.
Building Data Pipelines in Data Factory
Data Transformation with Azure Data Factory
Step 4: Scheduling and monitoring your data pipeline
Once you have built the pipelines, the next step is to schedule and monitor them. Scheduling determines when the pipelines run, and Azure Data Factory provides several options for scheduling pipelines. Monitoring your data pipeline is essential to ensure that it is running correctly. Azure Data Factory provides a monitoring dashboard that shows the status of your pipelines and alerts you to any issues.
Scheduling Pipelines in Data Factory
Monitoring and Alerting in Data Factory
Conclusion: Enjoying efficient data processing with Azure
Building a data pipeline with Microsoft Azure is a straightforward process that provides the perfect solution for processing data. With Azure, you can create a scalable, efficient, and secure pipeline that can handle any volume of data. By following the steps outlined above, you can create a data pipeline that meets your specific business needs. With Azure, you can enjoy efficient data processing, allowing you to make better, data-driven business decisions.



Thanks, I’ve been looking for this for a long time